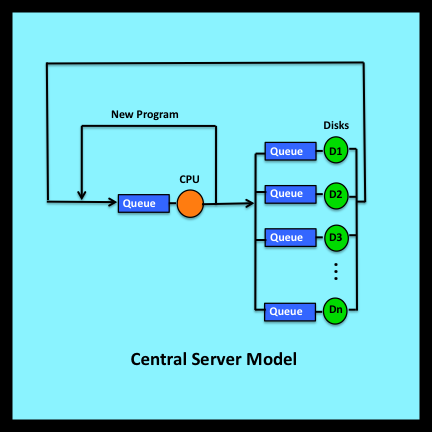
 Rethinking Randomness presents my thoughts on a puzzle I have been wrestling with for many years. In the early 1970s I developed a mathematical model that could predict the utilization levels, throughput rates and response times of large mainframe computer systems. The central server model, which is described briefly in Section 7.11.2, formed the basis of my PhD dissertation in Applied Mathematics at Harvard. As a theoretician, I was most interested in the challenge of creating realistic yet solvable analytic models and in developing algorithms that made their evaluation computationally feasible (Buzen’s algorithm: Wikipedia).
Rethinking Randomness presents my thoughts on a puzzle I have been wrestling with for many years. In the early 1970s I developed a mathematical model that could predict the utilization levels, throughput rates and response times of large mainframe computer systems. The central server model, which is described briefly in Section 7.11.2, formed the basis of my PhD dissertation in Applied Mathematics at Harvard. As a theoretician, I was most interested in the challenge of creating realistic yet solvable analytic models and in developing algorithms that made their evaluation computationally feasible (Buzen’s algorithm: Wikipedia).
Being the first of its type, the central server model quickly attracted the attention of practitioners who applied it to questions of importance within their own datacenters. As part of their investigations, these analysts validated their results by comparing predicted values of utilization, throughput and response time with actual measured values. The model proved remarkably accurate in practice.
I was delighted to learn of these successful validations. However, I was also puzzled by the fact that real world computer systems did not appear to satisfy the stringent mathematical assumptions that traditional queuing models require. This piqued my curiosity: why did these models exhibit such an unexpectedly high degree of accuracy? I have spent much of the past four decades investigating this issue and identifying conditions under which probabilistic models do, and do not, work well in practice.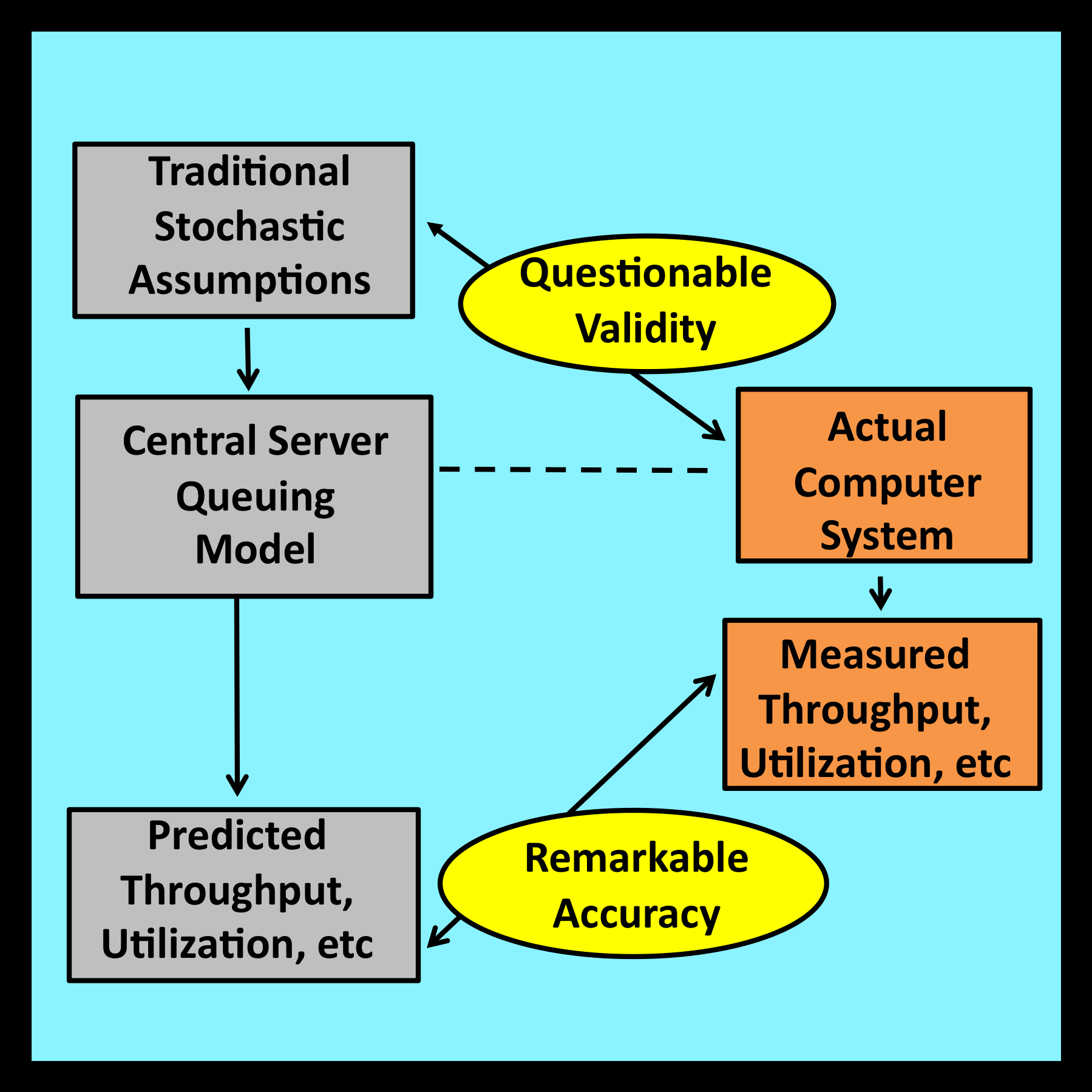
My first paper on this topic, “Fundamental Laws of Computer System Performance,” was published in 1976. It introduced the concept of operational analysis, an approach that mirrors the operational procedures practitioners follow when they apply certain mathematical equations to the analysis of real world systems. This paper received the inaugural “Test of Time” Award from ACM Sigmetrics in 2010, 34 years after its original date of publication.
Operational analysis has been integrated into a succession of major texts dealing with the analysis of computer performance (Ferrari, Serazzi and Zeigner 1983), (Lazowska, Zahorjan, Graham and Sevcik 1984), (Jain 1991), (Menascé, Almeida and Dowdy 1994), (Menascé and Almeida 2001), (Gelenbe and Mitrani 2010), (Harchol-Balter 2013), (Denning and Martell 2015). Nevertheless, it remains relatively unknown among engineers, experimental scientists and other practitioners who apply probabilistic models to problems in the physical, social and life sciences. A primary goal of this book is to recast the basic principles of operational analysis in a more general context so that its core ideas become accessible to this wider community.
Rethinking Randomness presents an introduction to observational stochastics, the successor to operational analysis. Observational stochastics extends the mathematical foundation of the original theory in several ways: most importantly, by formalizing the intuitive notion of observing and measuring the behavior of a system as it operates during an interval of time. Students enrolled in courses on probability and stochastic modeling should find observational stochastics particularly helpful in understanding how the material they are studying in class is actually applied in practice. And because all mathematical arguments are self contained and relatively straightforward, technically oriented non-specialists who wish to explore the connection between probability theory and the physical world should find much of the material in this book readily accessible.
I would like to thank my colleague Yaakov Kogan, formerly of Bell Labs and AT&T, for suggestions that have improved the clarity and strengthened the mathematical rigor of this book.
Jeffrey P. Buzen